天悦人声伴奏分离器
一款基于人工智能的高品质音频处理软件
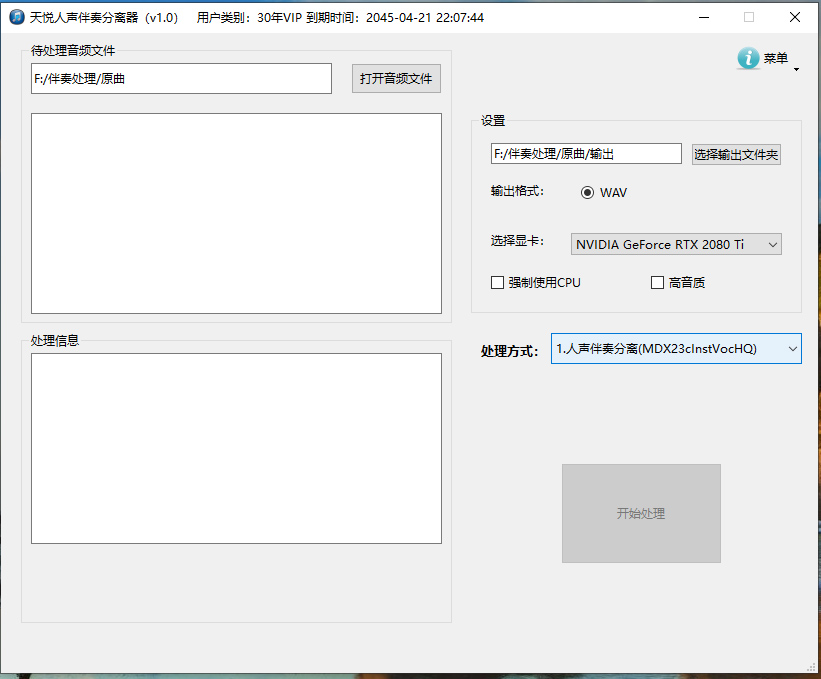
天悦人声伴奏分离器是一款基于前沿人工智能技术的专业音频处理软件,致力于为用户提供高效、高精度的人声与伴奏分离解决方案。通过深度学习算法,软件可精准识别并提取歌曲中的 vocal(人声)和 instrumental(伴奏)轨道,保留原始音质细节,轻松满足音乐制作、翻唱改编、K歌娱乐等多样化需求。既可以使用nvidia的显卡进行加速处理,没有独立显卡的用户也可以使用CPU进行处理。
一、核心功能和亮点
1.高品质的分离质量
拥有更高质量的AI模型,比广泛使用的UVR具有更高品质分离效果,分离出来音频效果出众,媲美原生伴奏,几乎感觉不到使用软件处理的痕迹,目前使用的AI处理模型有以下13个:
| 序号 | 模型名称 | 模型类型 | SDR得分 |
|---|---|---|---|
| 1 | 人声伴奏分离 | mdx23c | vocals:10.17 |
| 2 | 人声伴奏分离 | bs_roformer | vocals:10.99 |
| 3 | 高品质人声伴奏分离 | mel_band_roformer | instrumental: 16.69 vocals: 10.92 |
| 4 | 超高品质伴奏 | mel_band_roformer | instrumental:16.84 |
| 5 | 贝斯、鼓、人声、其他 | scnet | B: 11.27 D: 11.23 V: 9.05 O: 5.57 |
| 6 | 贝斯、鼓、人声、其他 | bs_roformer | / |
| 7 | 贝斯、鼓、人声、其他 | SCNetXL | / |
| 8 | 贝斯、鼓、人声、其他 | MDX23C | drums:10.80 |
| 9 | 卡拉OK带和声伴奏 | mel_band_roformer | vocals:10.20 |
| 10 | 去混响 | MDX23C | / |
| 11 | 去混响、回声 | mel_band_roformer | / |
| 12 | 降噪 | mel_band_roformer | / |
| 13 | 降噪(较激进) | mel_band_roformer | / |
排第一的MDX23C这个模型是UVR5.6这个版本能用的最佳处理模型,他的分离人声部分得分是10.17,排第二的bs_roformer模型在分离人声部分的得分为10.99,光看指标就知道要比MDX23C这个模型好,在实际听感上无论是分离出来的伴奏还是人声部分都明显好于前者,更不要说其他得分更高的模型了。
2.免费使用
只要通过本软件注册账号然后通过注册的账号密码登录软件,即可永久免费使用前面两个模型,这两个模型的处理效果已经非常不错,能满足大部分人的需要。新注册的账号能获得一天的VIP试用,VIP试用期过后你可以购买本软件VIP会员,推广期间的优惠价格为:永久VIP为49元,价格非常实惠,早买早享优惠价,后续随着版本升级可能会加价,VIP用户在使用期内升级新版本不再收取任何费用。
3.简单易用
全中文界面,各项设置一目了然,软件能记住你的使用设置,也可以设置自动录账号,不需要每次启动软件时都输入账号密码。
二、软件的下载和安装
软件有两个版本,分别是绿色版和安装版,下载链接在本文右侧栏,可以选择从百度网盘和123云盘下载。
绿色版下载后,拷贝到你要存放的目录后进行解压缩,会看到以下文件:
双击“天悦人声伴奏分离器”,即可运行软件,为方便日后使用,可以单击鼠标右键,把程序方式放到电脑桌面上。
安装版下载后解压,会看到以下几个文件,双击“天悦人声伴奏分离器安装程序”,根据提示安装到你想安装的目录,安装会件会在桌面创建快捷方式,安装版的安装时间稍长,需要耐心等待。

三、登录软件/注册用户
第一次启动软件,软件会弹出登录界面,需要输入账号、密码登录才能使用软件,软件启动的时间约需10秒左右,如果之前没有注册过账号,需要点击“新用户注册”按钮,点击后弹出注册界面:
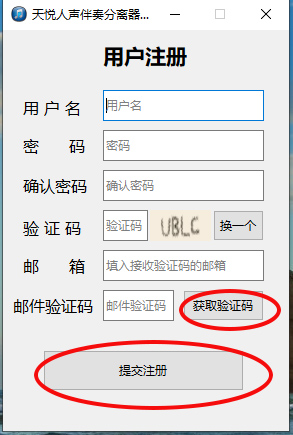
依次填写用户名、密码、确认密码、图形验证码和邮箱后,点击“获取验证码”按钮,你填入的邮箱会由到一封验证邮件,把验证邮件内的邮件验证码填入,再点击“提交注册”按钮即可完成注册。注册成功后关闭用户注册窗口,在用户登录窗口填写刚才注册的用户名和密码,再点击“登录”按钮即可进入软件的主界面。
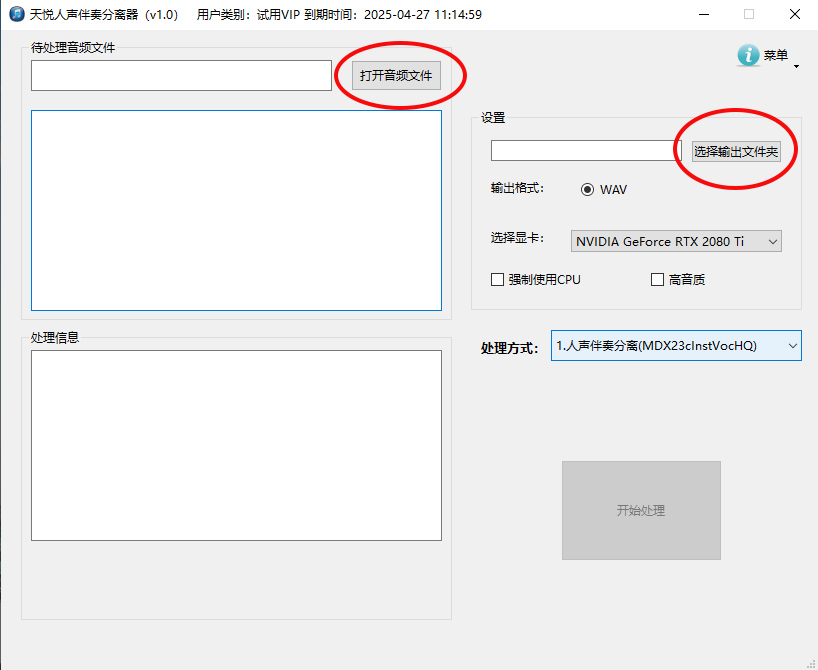
新注册的用户,软件提供1天的VIP试用。点击“打开音频文件”,选择要处理的1个或多个音频文件,再点击“选择输出文件夹”,设定分离后的音频文件存放路径,从处理方式的下拉框中选择需要的处理方式,然再点击“开始处理”按钮(没有选择文件,开始处理按钮为不可用状态)处理音频文件了。目前输出的格式只有“WAV”这一选项,如果你的显卡不支持本软件或没有安装显卡,可以勾选“强制使用CPU”这个选项,勾选“高音质”选项,可以稍微提高分离的质量,但处理时间为不勾选的3倍,请根据实际需选择。
四、分离音频
1.分离人声和伴奏
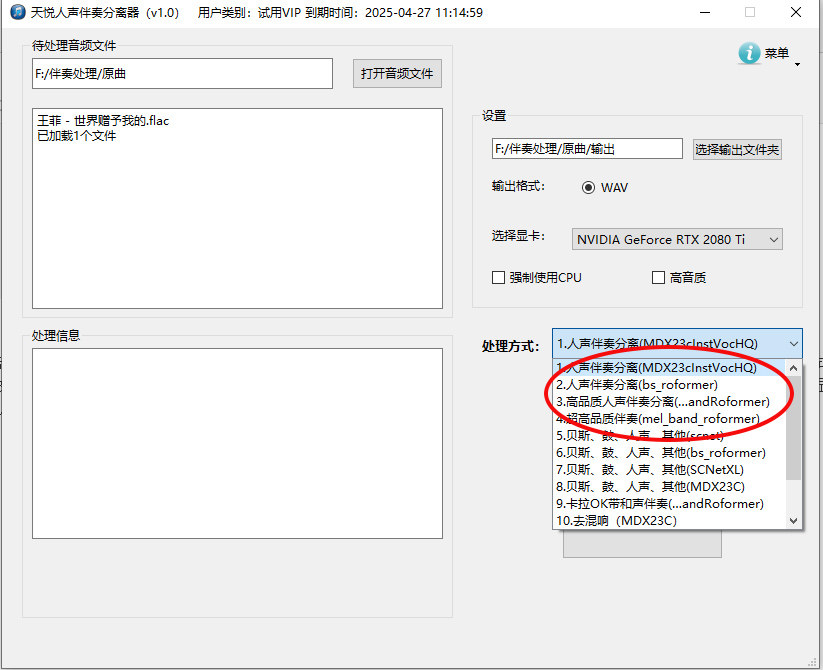
选择第1至第4这4个模型都可以分离出伴奏音乐和人声,分离出伴奏质量由高至低排列:4>3>2>1 ,分离人声的话2、3、4几个模型的质量都相当高,从指标上看模型2的人声质量最高,但还需要根据不同的音频选择不现的模型才能获得更好的效果。
2.分离贝斯和鼓点

要分离贝斯和鼓点,使用第5个至第8个模型都有不错的效果,推荐使用第5和第6个模型。
3.分离带和声的伴奏
使用模型9可以分离出带和声的伴奏,使用其他模型和声会和主人声会被分离到同一音频文件中。
4.去混响和回声
去混响和回声的用途是要是获得干声,训练人声AI模型需要用到干声,要得到干声就必须把人声中的混响 和回声去除,具体分两步走:第一步,使用模型1至模型4的其中一个模型分离出伴奏和人声;第二步,把第一步中分离出来的人声音频文件进行一次去混响或去回声处理,即选择模型10或模型11进行处理,即可得到较为干净的干声。
5.降噪处理
一些街头的采访 ,或者是在一些嘈杂环境中的录音,可以通过降噪处理获得背景安静的人声,这里我们选择模型12或模型13来进行降噪处理。
五、待办事项
接下来,将加入更高质量的处理模型,同时考虑增强老视频、老录音的修复功能。